近日,我院郭浩教授团队在计算机视觉领域方向取得新进展,相关成果论文《An RGB-Event Hierarchical Fusion Enhancement Network for Object Detection》(DOI:10.1109/TCSVT.2026.3702213)发表在国际视频技术领域权威期刊IEEE Transactions on Circuits and Systems for Video Technology (IEEE TCSVT)。该论文第一署名单位为太原理工大学,计算机科学与技术学院(大数据学院)硕士研究生王凯一为第一作者,程忱副教授、郭浩教授及清华大学邓磊副教授为共同通讯作者。
IEEE Transactions on Circuits and Systems for Video Technology是视频技术与电路系统领域最具国际影响力的顶级期刊之一,为中国计算机学会(CCF)推荐的B类期刊,同时也是中科院分区一区TOP期刊,影响因子11.1。该期刊主要发表视频处理、图像编码、计算机视觉、多媒体系统等方向的前沿创新研究成果,在学术界与工业界享有极高声誉。
目标检测是计算机视觉领域的核心任务之一,在自动驾驶、智能监控、机器人导航等应用中发挥着关键作用。然而,传统基于帧的相机在低光照、过曝光以及高速运动等复杂场景下,由于电容容量的固有限制,成像质量急剧下降,导致目标检测性能严重退化。事件相机作为一种新型仿生视觉传感器,通过像素独立电路异步感知光强变化,具有高时间分辨率、高动态范围和稀疏数据输出等独特优势,为突破传统相机的感知瓶颈提供了新的技术思路。然而,由于事件数据的异步稀疏特性,单纯基于事件相机的检测方法在精度上往往低于传统图像方法。如何高效融合事件与帧两种异构模态数据,实现优势互补,成为该方向亟待解决的核心挑战。
针对上述挑战,研究团队提出了一种分层融合增强网络FENET(Hierarchical Fusion Enhancement Network)。首先,针对传统稠密表示对事件时间尺度信息利用不足的问题,设计了可学习的多时间尺度事件预处理模块,通过生成时间聚合帧,综合利用从标准RGB曝光时间到更精细微秒级时间尺度的事件数据,确保目标结构的完整捕获与清晰刻画。其次,提出了双分支自适应增强跨模态聚合模块,创新性地先对各模态特征进行自增强,再由全局上下文与局部空间信息共同引导自适应融合,从而实现高效、鲁棒的多模态特征聚合。
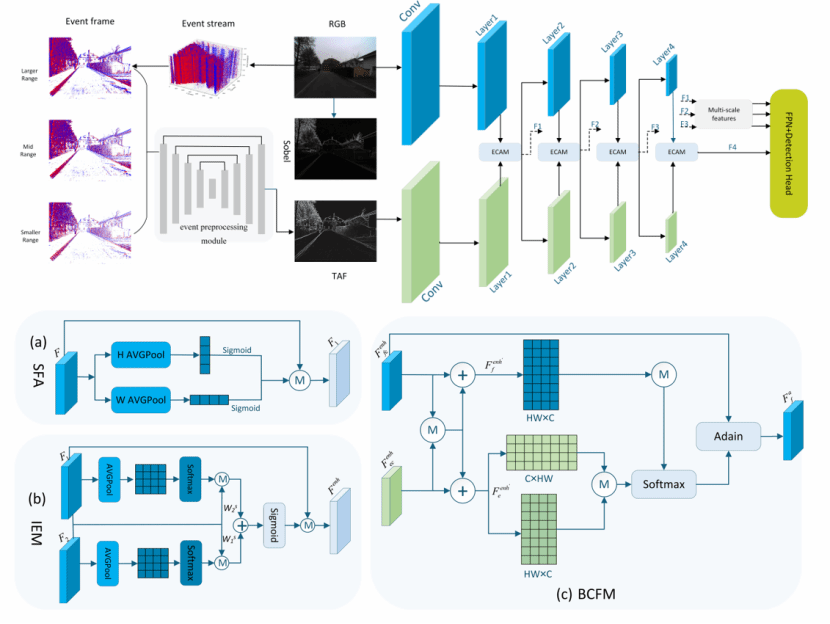
图1 FENET算法整体框架
此外,为解决事件目标检测领域大规模高质量标注数据集匮乏的瓶颈,研究团队自采集构建了DSEC-D数据集,涵盖60个序列、70,739张图像及超过25万个高质量标注,为该领域的研究提供了宝贵的数据基础。

图2 自建DSEC-D数据集中不同光照条件样例
研究团队在多个公开基准数据集上开展了全面的实验验证,与当前十余种最先进的目标检测方法进行了系统对比。实验结果表明,FENET在mAP50指标上相较当前最佳的RGB-EVENT融合方案FRN提升了8.6%,在更严格的mAP50:95指标上提升了3.7%,综合性能显著优于现有方法。此外,消融实验进一步验证了各模块设计的有效性与必要性。
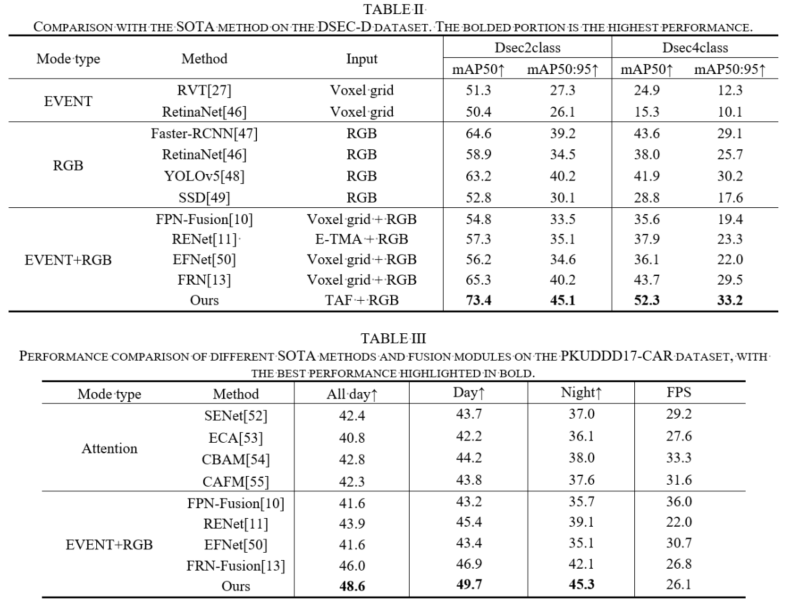
图3 实验结果对比
郭浩教授团队的该项研究为多模态融合目标检测提供了创新性的技术方案,充分体现了我院在脑启发计算、计算机视觉与人工智能交叉学科方向的科研布局与创新能力。未来,郭浩教授团队将持续在类脑计算、多模态感知等前沿方向深入探索,推动研究成果向工业实际应用场景转化。学院也将进一步推进高水平科研平台建设,大力支持研究生开展原创性、前沿性科研工作,助力更多高质量成果走向国际学术舞台。
 学校主页
学校主页
 新闻动态
新闻动态

