近日,我院郭浩教授课题组与清华大学合作,提出了一种在类脑计算芯片架构上加速宏观脑动力学建模的方案。该方案旨在解决宏观脑动力学模型在参数辨识(模型反演)过程中计算量巨大、耗时严重的问题。研究团队首次系统性地设计了面向复杂脑动力学模型的量化框架,并提出了针对“天机芯”类脑计算芯片的层次化并行映射策略,成功将大规模脑模型部署到低精度、高并行的类脑众核芯片上,在保持模型功能高保真度的同时,实现了数十至数百倍的性能加速。这一成果不仅为脑动力学建模提供了重要的计算基础设施,也为类脑计算芯片在神经科学和医学等科学计算领域的应用提供了思路。
相关研究成果以“Modeling Macroscopic Brain Dynamics with Brain-inspired Computing Architecture”为题,2025年10月24日发表于《自然•通讯》(Nature Communications)。我院已毕业博士魏静为该论文的共同第一作者,我院郭浩教授为第一通讯作者。

研究背景与成果
大脑功能的理解高度依赖于大规模神经网络的建模与仿真。当前存在两种主要建模方法:细粒度建模(以神经元为单位)虽然细节丰富,但因参数量巨大、数据获取困难,难以应用于全脑尺度;粗粒度建模(以神经元群或脑区为单位)更适合现阶段的大规模脑模拟,它能融合fMRI、dMRI等多模态数据,构建数据驱动的全脑模型(数字孪生脑)。然而,粗粒度模型的模型反演过程计算量极大,需要反复进行长时间动态仿真,传统CPU算力严重不足,这极大地限制了科研效率和临床应用潜力。
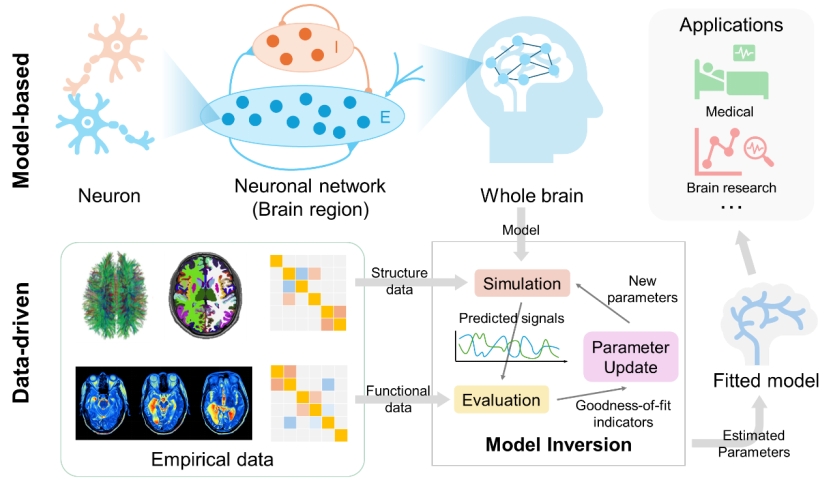
图1 数据驱动的宏观脑动力学建模
以天机芯等为代表的类脑计算芯片,因其高度并行的多核架构和高能效特性,为加速脑动力学仿真提供了新思路。然而,这些先进计算架构与粗粒度脑动力学模型的应用之间存在着巨大的鸿沟。类脑计算芯片主要面向低精度、智能计算负载(如各类神经网络任务),而脑动力学仿真属于高精度、科学计算范畴。现有的量化方法无法直接应用于状态变量时空异质性强、需要长期数值稳定性的动力学模型。同时,类脑计算芯片以神经元而非神经元群或脑区为基础单元的架构设计,也给粗粒度模型的部署带来了挑战。
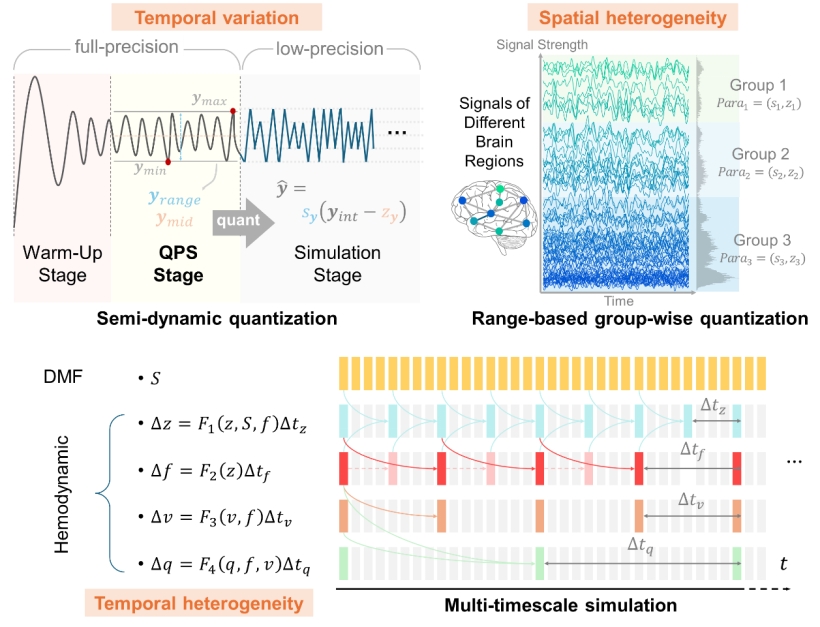
图2 低精度量化用于动力学系统仿真面临的挑战与解决方案
为解决上述挑战,研究团队提出了一套利用类脑计算芯片加速宏观脑建模的计算流程,旨在让宏观脑动力学模型充分利用现代先进计算架构的优势。该流程包含两大核心部分:在算法层,设计了动力学感知的量化框架,针对动力学系统的时间动态性、空间异质性和时间异质性特征,通过半动态量化、分组量化和多时间尺度仿真等策略,首次实现了复杂动力学模型在低精度整数平台上的稳定、长时程模拟。在映射层,提出了层次化并行映射策略,将模型反演过程中的多层次并行性高效地映射到类脑计算芯片和GPU的并行存算资源上,实现了对存算资源的充分利用。
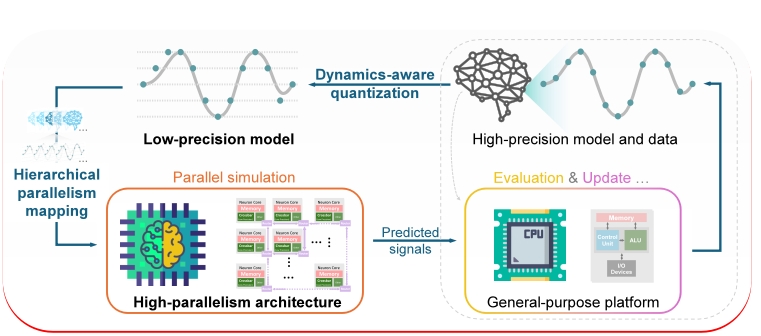
图3 使用类脑计算芯片加速宏观脑动力学建模的计算流程
成果优势
该工作最核心的优势表现为显著的运行性能提升。相比于CPU基准,模型在“天机芯”类脑计算芯片上实现了75至424倍的仿真加速,将宏观脑动力学模型辨识这一耗时巨大的关键步骤所需时间压缩到分钟级别;进一步,类脑计算芯片的加速效果也优于算力接近的GPU,优势随任务规模增大而增大。其次,提出的低精度脑动力学模型在多模态神经影像数据上仿真特性和参数估计结果与高精度的浮点模型高度一致,验证了方法的可靠性,同时揭示了低精度量化对欧拉积分步长的约束作用,并分析了低精度量化对仿真结果的影响的作用机制。
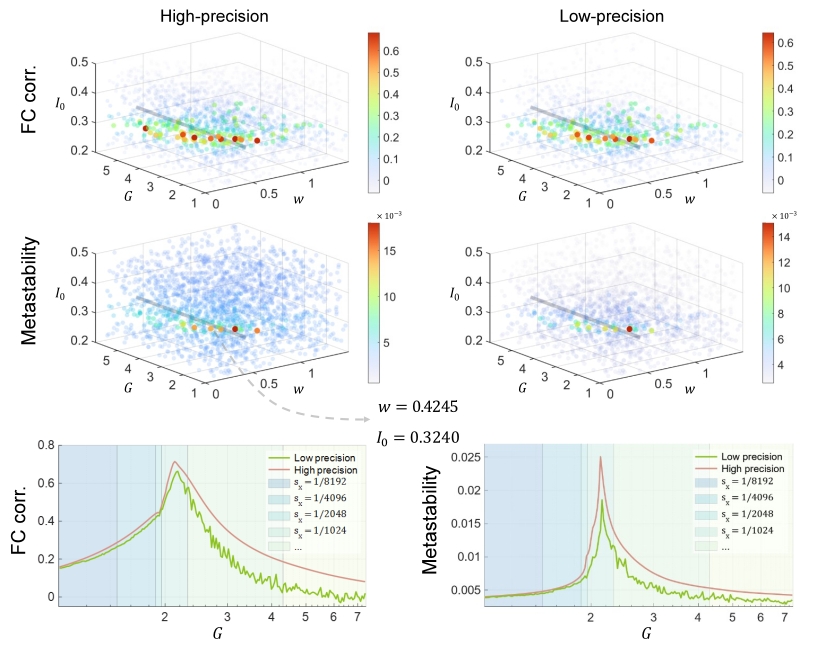
图4 低精度模型仿真得到的拟合优度与高精度模型结果在参数空间中接近
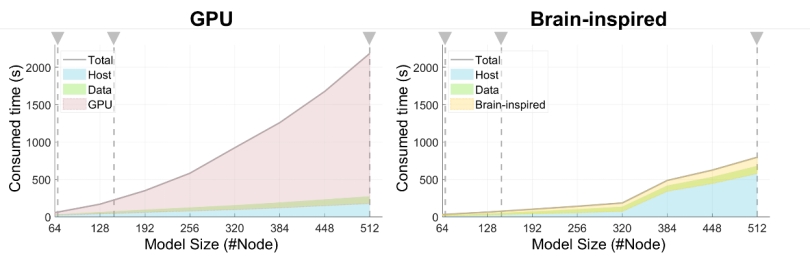
图5 基于类脑计算芯片的仿真速度相比GPU明显更快
未来展望
该工作有望大幅提高了神经科学领域的建模效率,使得研究人员能够快速迭代模型、测试假说,还为开展更大规模、更长时间尺度的全脑动力学仿真奠定了算力基础。通过大幅降低个体化全脑建模的时间成本,为该技术的在医疗领域的应用提供了思路。未来,基于个体大脑模型进行脑疾病(如癫痫、抑郁症)的机制分析、疗效预测以及个性化神经调控(如深部脑刺激)方案的优化将变得更加可行。同时,该工作也成功拓展了类脑计算芯片的应用边界,证明了其不仅擅长处理各类智能任务,在神经科学、生物物理等科学计算领域同样拥有巨大潜力,推动了新兴计算架构与前沿基础科学的深度融合。
论文链接:https://www.nature.com/articles/s41467-025-64470-3
 学校主页
学校主页
 新闻动态
新闻动态

